En finir avec les réseaux routiers en spaghetti
Vous êtes-vous déjà demandé comment les cartographes choisissent quelles routes afficher et lesquelles laisser de côté sur une carte ? Autrefois, les cartographes décidaient manuellement quelles routes étaient importantes à l’échelle représentée. À des échelles relativement petites, comme pour une carte de l’ensemble des États-Unis (1:50.000.000), la grande majorité du réseau routier ne peut pas être affichée par manque d’espace. La sélection est donc très stricte : seules les routes les plus importantes de la zone doivent apparaître. Cela dépend fortement du contexte, ce qui demande au cartographe de disposer de nombreuses informations. C’est un travail très long et minutieux. Il était donc naturel que ce processus soit aujourd’hui pris en charge par l’ordinateur.
Mais la question est la suivante : comment faire en sorte que l’ordinateur effectue cette sélection automatiquement ?
Avant d’entrer dans le détail, nous allons d’abord vous présenter notre source de données. Nous utilisons OpenStreetMap, un projet open source dans lequel de nombreux bénévoles, partout dans le monde, consacrent des heures à cartographier notre planète. C’est une très belle initiative : elle nous offre une carte mondiale qui ne cesse de s’améliorer. Elle présente toutefois un inconvénient. La qualité et la cohérence des données ne sont pas aussi élevées que celles d’un jeu de données soigneusement élaboré par des cartographes professionnels.
Chaque route dans OpenStreetMap possède une catégorie. Voici ce que nous avons fait ces dernières années : à chaque niveau de zoom, nous définissons une catégorie minimale de route à afficher. Cela signifie que plus vous zoomez (donc plus l’échelle est grande), plus de routes apparaissent. À l’inverse, plus vous dézoomez, moins de routes sont visibles.

Cette méthode donne de bons résultats dans certaines zones, et de moins bons dans d’autres. Comme nous avons à cœur de créer les meilleures cartes possibles, cela ne nous satisfaisait pas. Les images ci-dessous montrent quelques situations qui ne sont pas optimales. En haut, nous voyons deux zones où les routes sont si nombreuses et si proches les unes des autres qu’elles perdent leur lisibilité. En dessous, nous voyons au contraire des zones si clairsemées que certaines routes semblent s’interrompre au milieu de nulle part, ou bien qu’il n’y a presque pas de routes du tout.




Comme vous pouvez le constater, il existe un décalage entre ce que nous voulons afficher (les routes les plus importantes du réseau routier) et ce que nous sélectionnons réellement (la catégorie de route dans OpenStreetMap). C’est pourquoi nous avons développé un algorithme de sélection alternatif.
Au lieu d’inclure ou d’exclure des routes selon leur catégorie, nous partons de toutes les catégories de routes et supprimons progressivement des routes jusqu’à ce qu’aucune zone ne soit trop chargée. Pour décider quelles routes retirer lorsqu’une zone est trop dense, nous nous appuyons sur leur catégorie. Les routes de catégorie inférieure sont supprimées en premier. Ce n’est que lorsqu’il n’en reste plus dans la zone que les routes de niveau supérieur sont retirées. En complément, les routes appartenant à de grands réseaux routiers, comme les routes européennes en Europe ou les Interstate Highways aux États-Unis, sont considérées comme plus importantes. Nous supprimons également toutes les impasses. Cela nous a permis d’obtenir une sélection du réseau routier qui met en avant les routes les plus importantes dans chaque zone, selon le contexte :
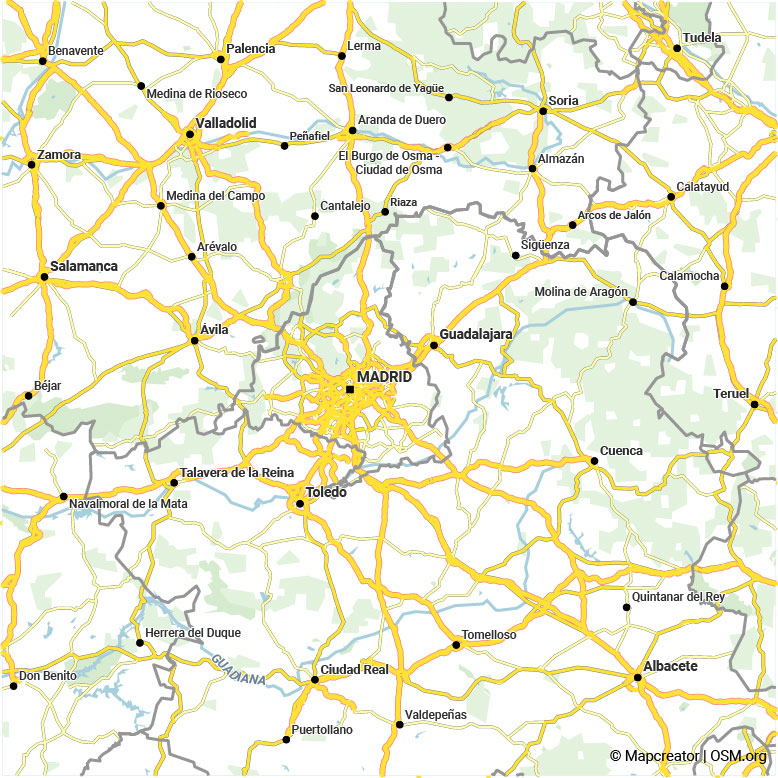
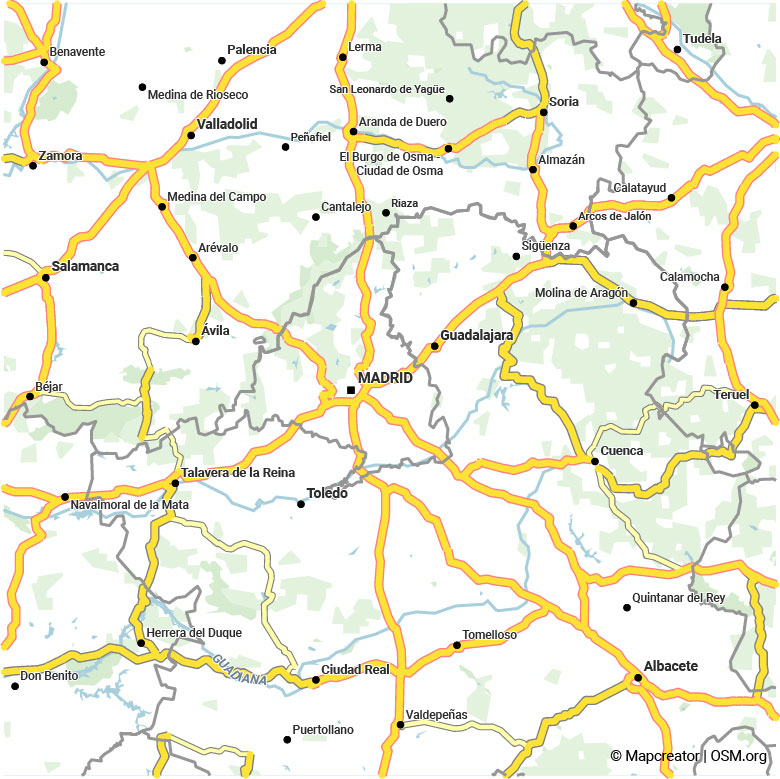
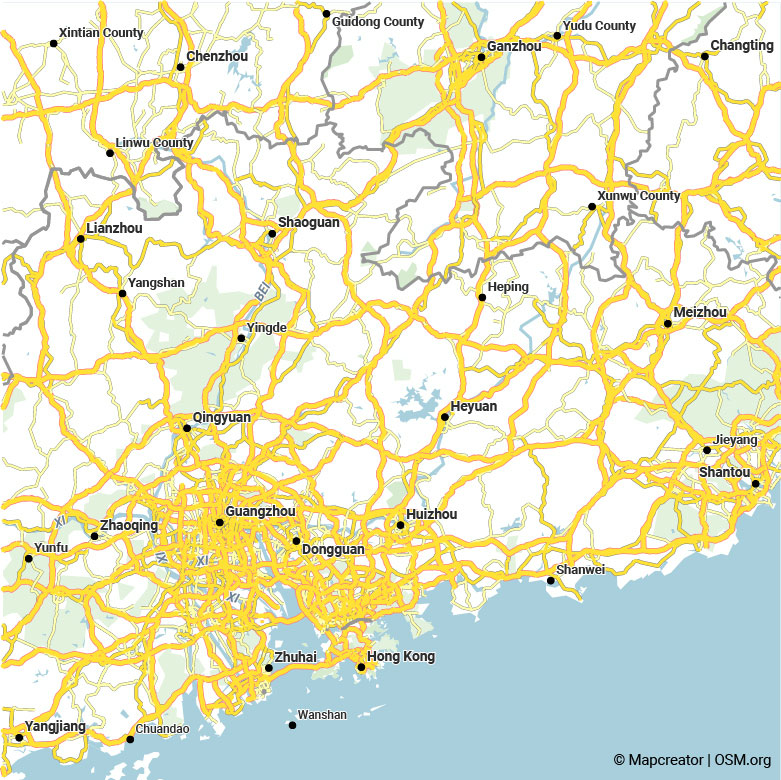
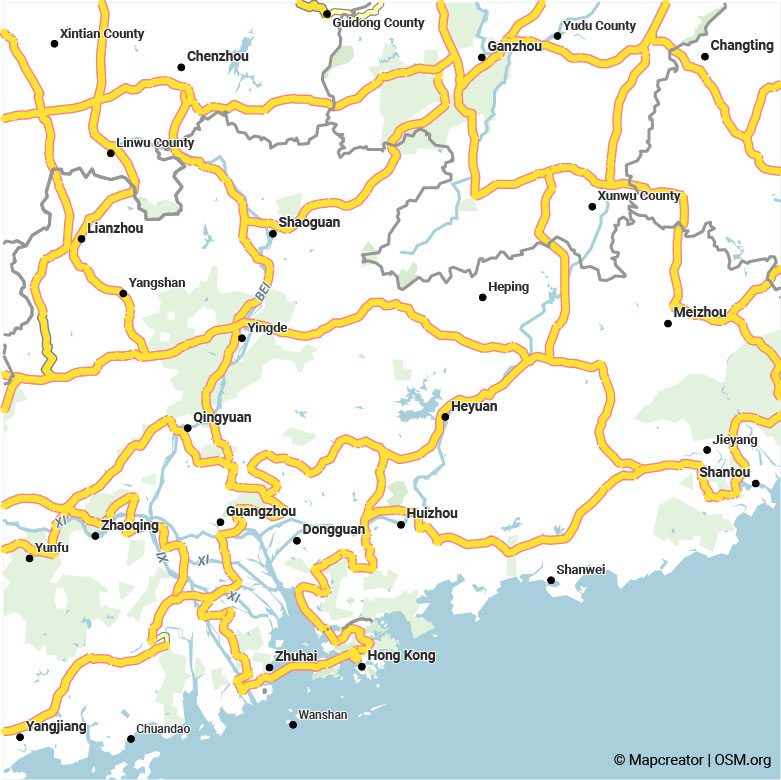
Comparaison visuelle entre l’ancienne sélection basée sur les catégories de routes (à gauche) et l’algorithme de sélection amélioré (à droite). Faites glisser le curseur pour comparer les images. Dans ces zones auparavant très chargées, seuls les réseaux routiers les plus importants ont été conservés à droite.
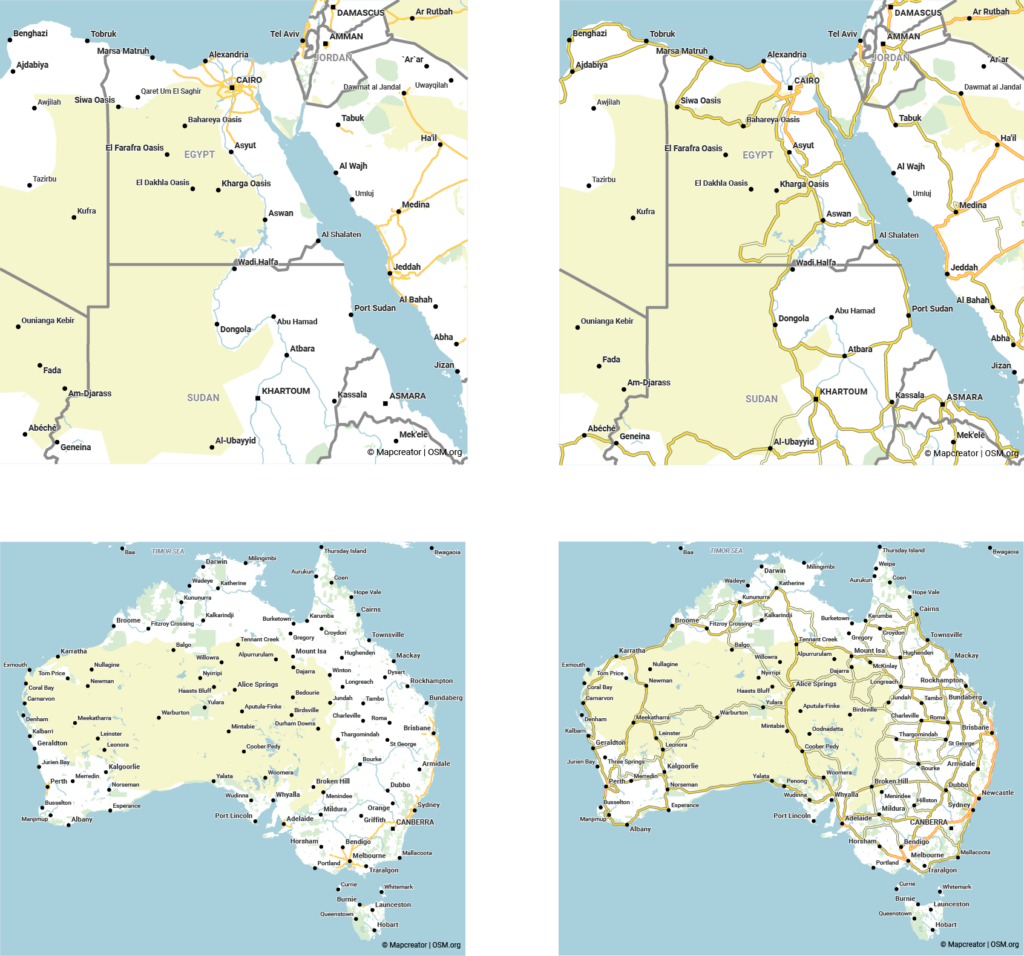
Comme vous pouvez le constater, le réseau routier présente désormais une densité bien plus homogène. Dans les zones très denses, comme autour de Madrid, une sélection est effectuée afin que la carte soit beaucoup plus lisible et pertinente. Dans les zones auparavant très clairsemées, comme en Afrique du Nord, nous voyons maintenant un réseau routier connecté qui couvre aussi des régions où les routes sont de moindre qualité.
Vous l’aurez compris, nous avons à cœur de créer les meilleures cartes possibles. Nous considérons qu’il s’agit déjà d’une amélioration majeure, en particulier dans les zones qui étaient auparavant soit très denses, soit très clairsemées. Toutefois, dans certaines zones, il reste difficile de dire si l’ancienne ou la nouvelle approche est meilleure. Par exemple, certaines routes que nous jugeons importantes ont pu être supprimées par l’algorithme de sélection. Nous ne comptons donc pas nous arrêter là. Vous pouvez vous attendre à ce que nous continuions à améliorer cette méthode et à trouver des moyens d’appliquer cet algorithme à d’autres couches.
Si vous souhaitez utiliser ce nouveau réseau routier généralisé dans vos cartes et que vous ne le trouvez pas encore dans notre outil, veuillez contacter notre équipe Support.
N'oubliez pas de partager cet article !
Comprendre les cartes en profondeur
Conseils, actualités et analyses approfondies pour les passionnés de cartographie.
Ce que le 30 Day Map Challenge nous a appris sur la créativité (et sur Mapcreator)
Chaque mois de novembre, cartographes, designers et passionnés de data se retrouvent autour du même feu de camp mondial :...
Lire la suite
Comment les cartes statiques, interactives et animées séduisent (et génèrent des clics)
La concurrence pour capter l’attention est partout. Vidéos de chats, doomscrolling, dernière saison de [insérez ici votre série préférée]... Alors,...
Lire la suite
Améliorations de l’animation : les trajectoires de caméra sont désormais plus fluides que jamais !
Chez Mapcreator, nous travaillons en permanence à mettre à jour et à améliorer notre outil. Lorsque nous avons lancé la...
Lire la suite
Terrain 3D — Donnez une nouvelle dimension à vos projets cartographiques
Êtes-vous prêt à faire passer vos animations cartographiques à un tout autre niveau ? Préparez-vous à donner une nouvelle dimension...
Lire la suite
Visualisez la guerre en Ukraine : découvrez la nouvelle couche de données en direct
Couvrir la guerre en Ukraine est d’une importance capitale, car cela permet de mettre en lumière l’un des conflits géopolitiques...
Lire la suite
Mapcreator, l’alternative à Google Maps
Pour la navigation, Google Maps est une excellente solution. Mais si vous recherchez un véritable outil de cartographie, Mapcreator vous...
Lire la suite